JimuChatBI 介绍与建模配置
本文面向管理员,讲解 JimuChatBI 的功能与建模配置。如何把模块集成到项目,见 JimuChatBI 快速集成;业务用户如何提问取数,见 JimuChatBI 问数对话使用。
1. 功能介绍
JimuChatBI(积木问数 / Chat2BI) 是积木报表的对话式 BI(自然语言问数)模块。业务人员不用懂 SQL、不用画报表,像聊天一样提问,AI 即自动理解、生成查询、取数,并以表格 + 图表 + 一句话洞察返回。
核心能力:
- 自然语言取数:0 SQL 学习成本
- 口径可视化调整:直接切换指标 / 维度,改完即时重算
- 多种输出:表格、图表、智能洞察、可查看 SQL
- 结果可沉淀:一键另存报表 / 加入大屏 / 导出 / 生成报告
- 企业级安全护栏:访问授权、敏感词、行级 / 列级权限、敏感度分级
- 术语映射:业务口语、简称、近义词对齐到精确口径
JimuChatBI 以独立 JAR 形式提供,像积木报表一样可快速集成到 Spring Boot 2 / Spring Boot 3 项目中,集成步骤见 快速集成。集成后访问入口为
/chat2bi/index(上下文路径取决于宿主应用)。本文以内置「保险分析域」示例数据演示。
2. 核心概念与整体流程
配置遵循"由下而上"的链路,理解 5 个概念即可掌握全貌:
| 概念 | 说明 |
|---|---|
| 数据源 | 数据库连接,数据从这里读取。可复用积木报表数据源或单独新增 |
| AI 数据表 | 库表的元数据 + 业务描述,并控制哪些表对 AI 可见(描述越清晰,问数越准) |
| 数据域(语义建模) | 问数的语义边界:注册表、配关联、主题、术语与权限 |
| 对话助理 | 面向用户的问数机器人,绑定一个数据域后上线 |
| 对话 | 用户与助理的多轮问答记录 |
配置数据源 → 维护 AI 数据表 → 语义建模(数据域) → 创建对话助理 → 用户对话问数
(连数据库) (表/字段描述) (注册表/关联/术语/权限) (绑定域/上线) (自然语言提问)
3. 界面总览
顶部 5 个模块对应完整链路:
| 模块 | 用途 | 使用者 |
|---|---|---|
| 问答对话 | 提问、查看结果 | 业务用户 |
| 助理管理 | 创建 / 上下线助理 | 管理员 |
| 语义建模 | 数据域:表 / 关联 / 主题 / 术语 / 权限 | 管理员 |
| AI 数据表 | 维护库表描述与 AI 可见范围 | 管理员 |
| 数据源 | 新增 / 测试数据库连接 | 管理员 |
建模配置分四步:数据源 → AI 数据表 → 语义建模 → 助理,下面依次说明。
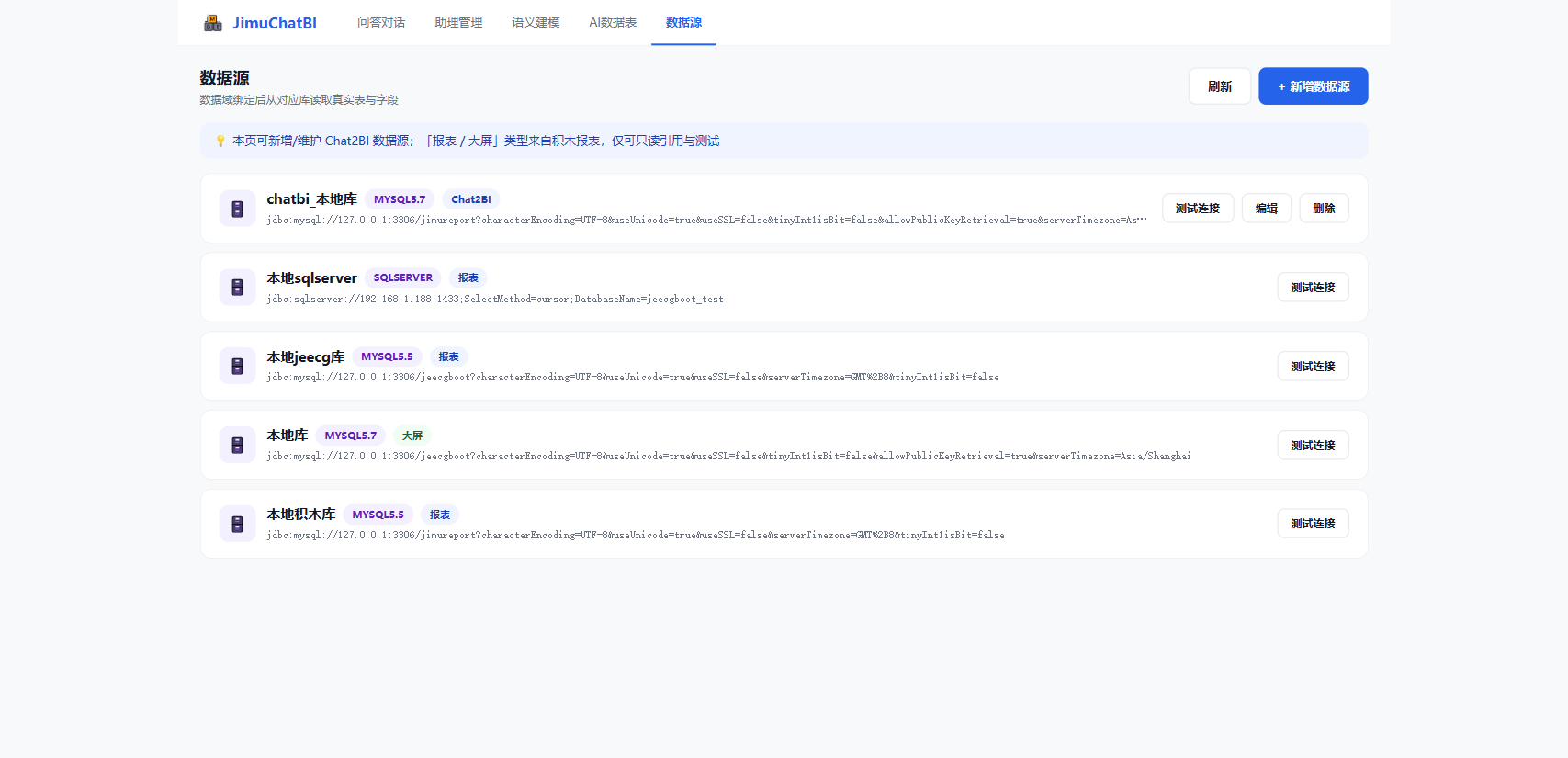
4. 配置数据源
进入 「数据源」,管理可访问的数据库连接(页面也会列出积木报表的「报表 / 大屏」数据源,仅可只读引用与测试)。
点击 + 新增数据源,填写连接信息:
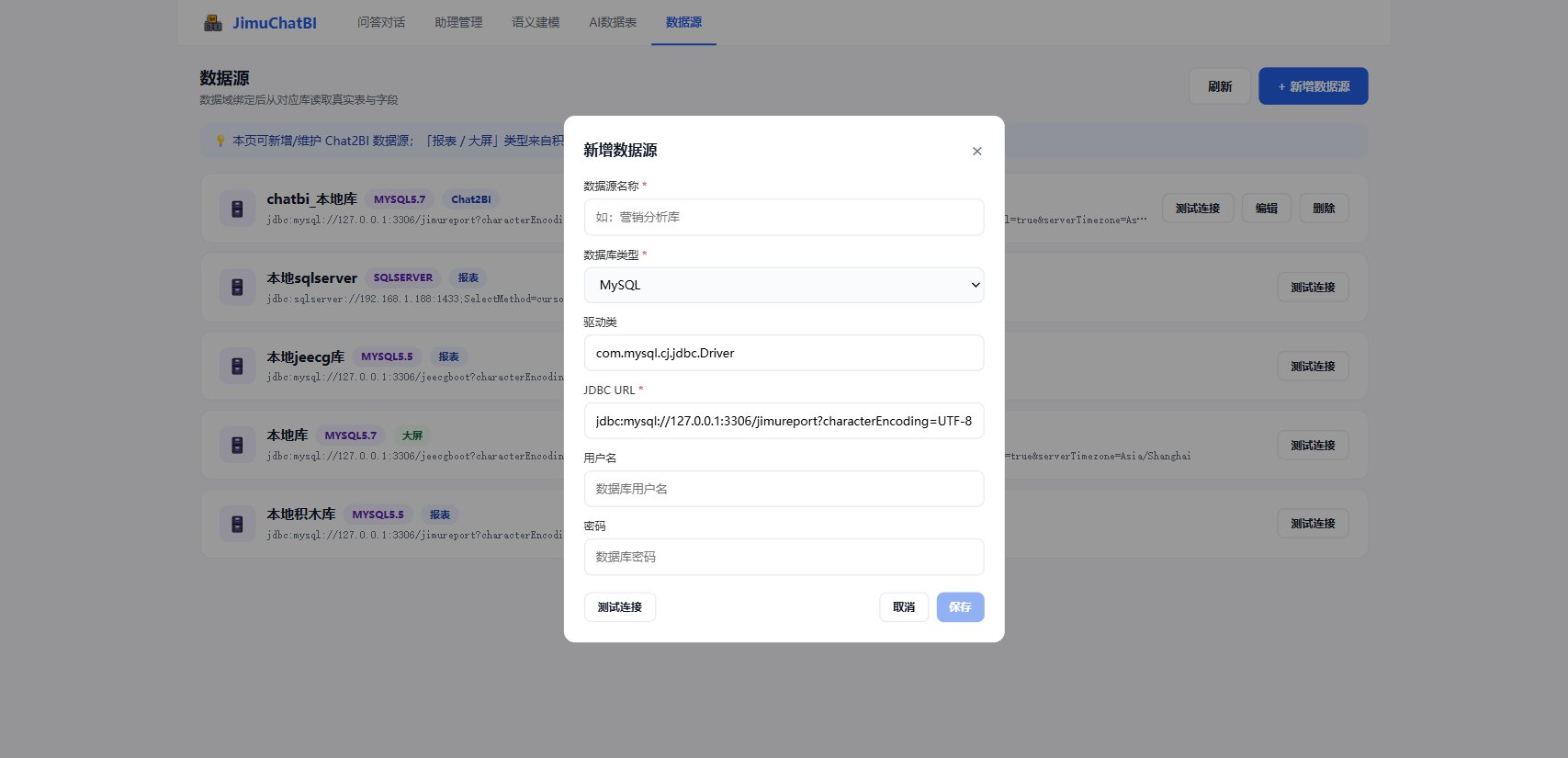
| 字段 | 说明 |
|---|---|
| 数据源名称 | 必填,便于识别 |
| 数据库类型 | 必填,切换后自动带出驱动类 |
| JDBC URL | 必填,如 jdbc:mysql://host:3306/db?useUnicode=true&characterEncoding=utf8 |
| 用户名 / 密码 | 数据库账号(编辑时密码留空表示不改) |
支持类型: MySQL、TIDB、Oracle、SQLServer、MariaDB、PostgreSQL、达梦、人大金仓、神通、DB2、Hsqldb、Derby、Doris、SQLite。
保存前先点 「测试连接」 验证。密码以 AES 加密存储,不会明文落库。
5. 维护 AI 数据表
进入 「AI 数据表」,维护库表结构、业务描述并控制对大模型(LLM)的可见范围。描述越清晰,问数越准。
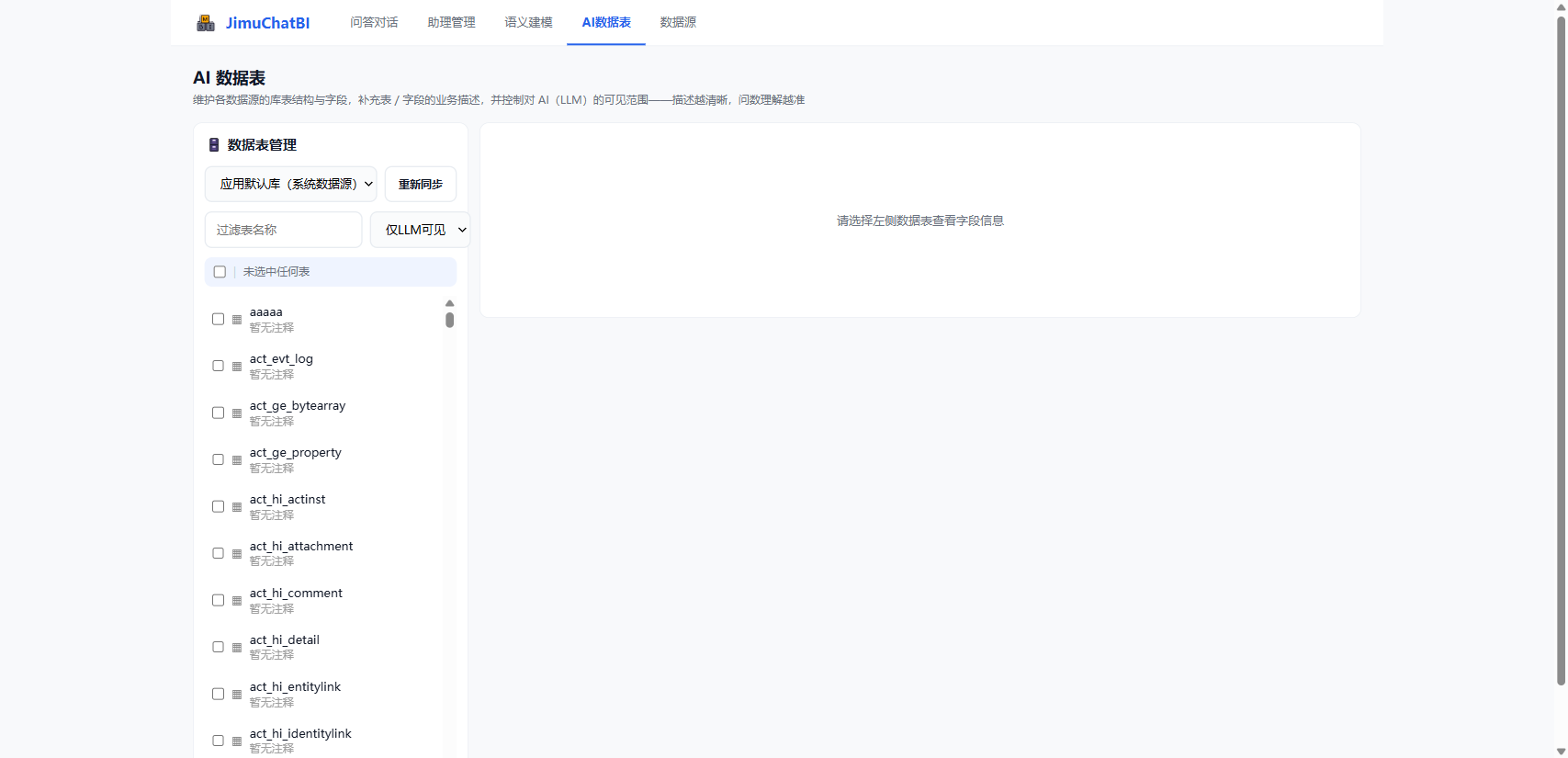
左栏(数据源 + 表清单): 切换数据源 → 点 「重新同步」 拉取库表 → 可按表名过滤、按 LLM 可见性筛选;勾选后可批量设为可见 / 不可见(只有"可见"的表才参与问数)。
右栏(表详情): 点击左侧表查看详情:
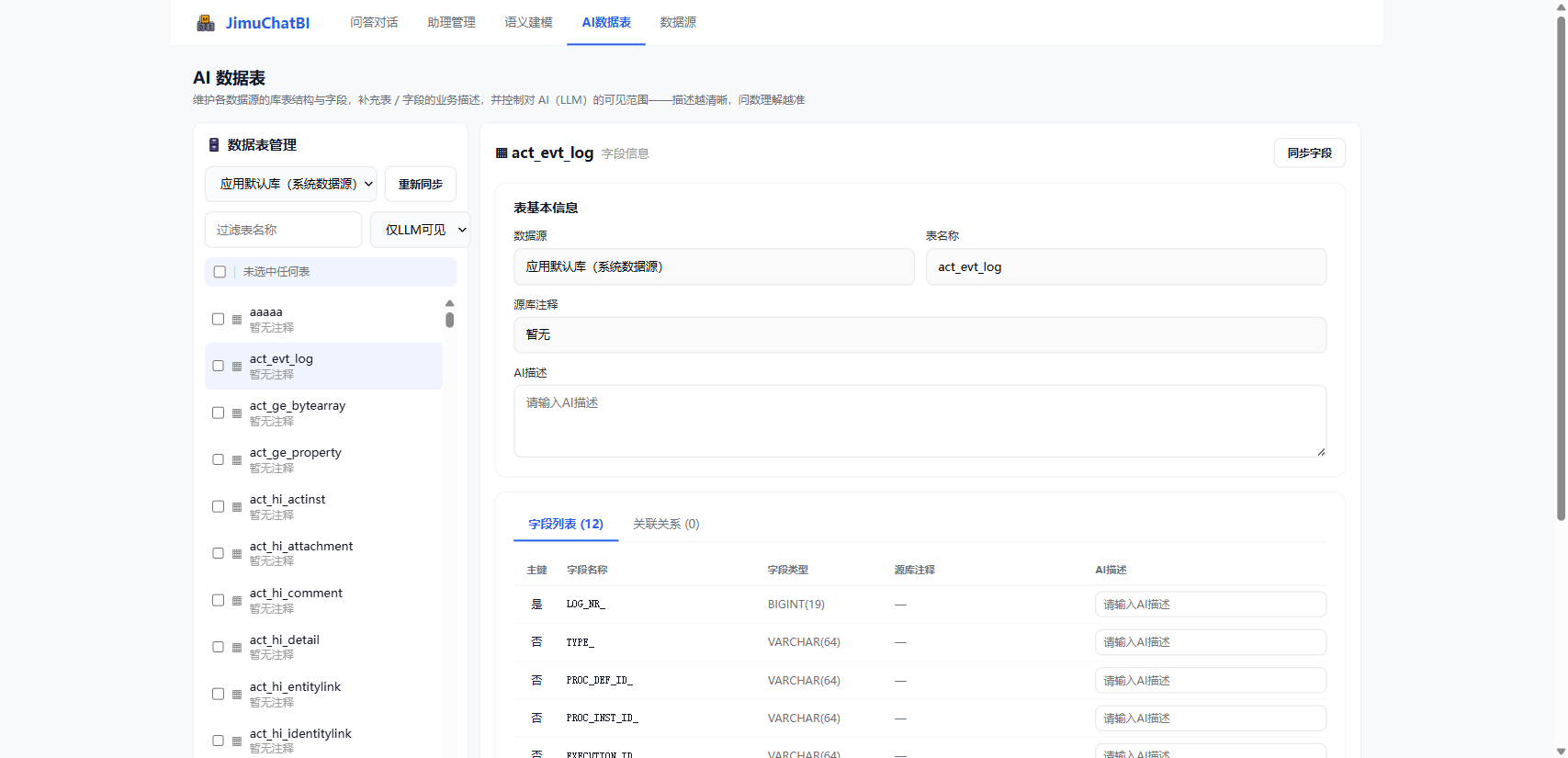
- 表 / 字段 AI 描述:用业务语言描述表和字段(如
cust_level→ "客户等级") - 关联关系:维护本表与其他表的外键关联,供跨表问数
把字典字段(性别、状态码等)也描述清楚,AI 取数与码值翻译会更准。
6. 语义建模(数据域)
进入 「语义建模」,以数据域为单位组织问数语义。
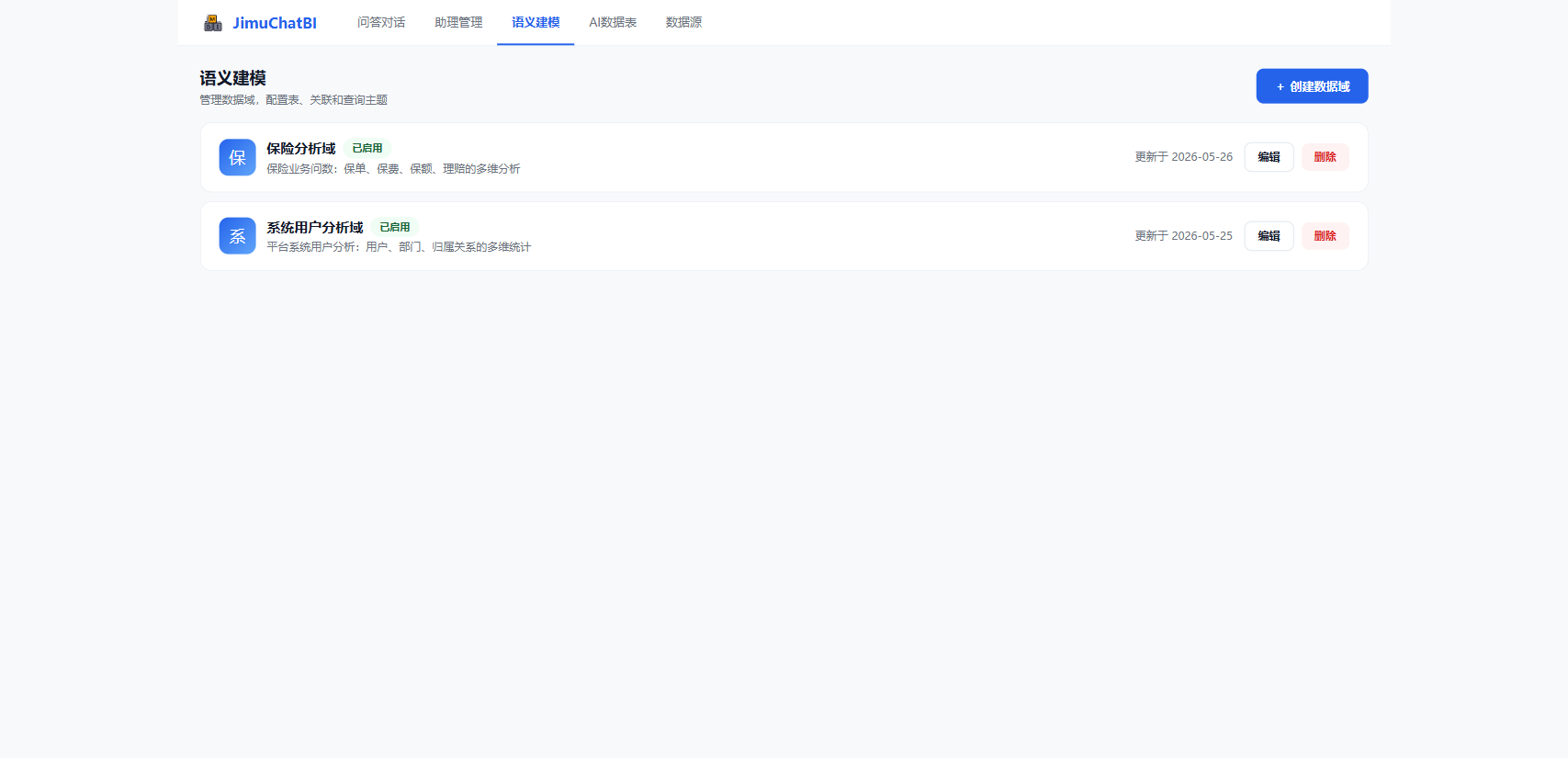
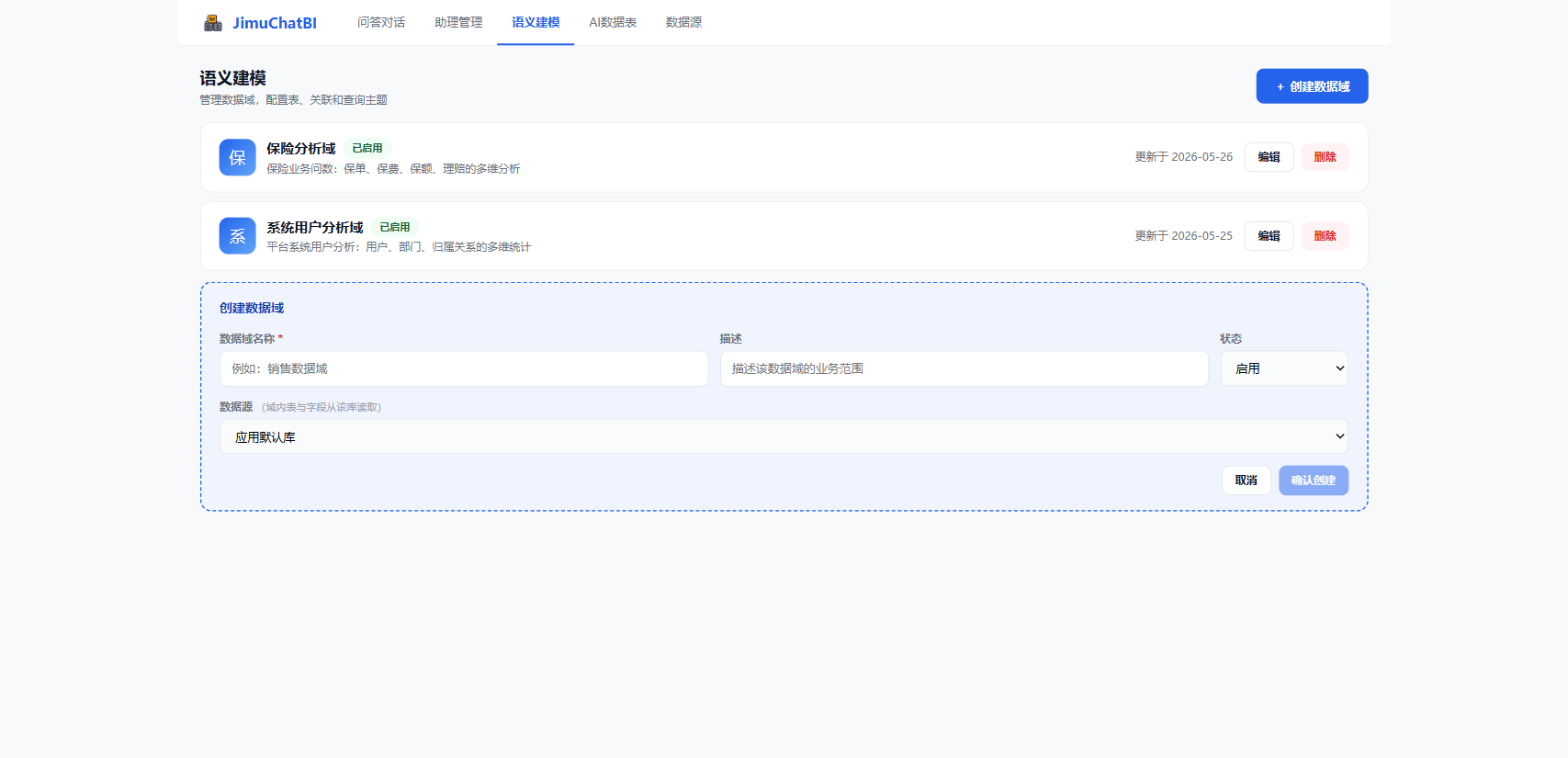
点击 + 创建数据域,填名称、描述,并选择读取数据的数据源(不选则用应用默认库):
进入数据域后有 5 个子页:表注册 / 关联管理 / 查询主题 / 术语管理 / 权限管理。
6.1 表注册
把数据源的表注册进来,并定义字段角色。
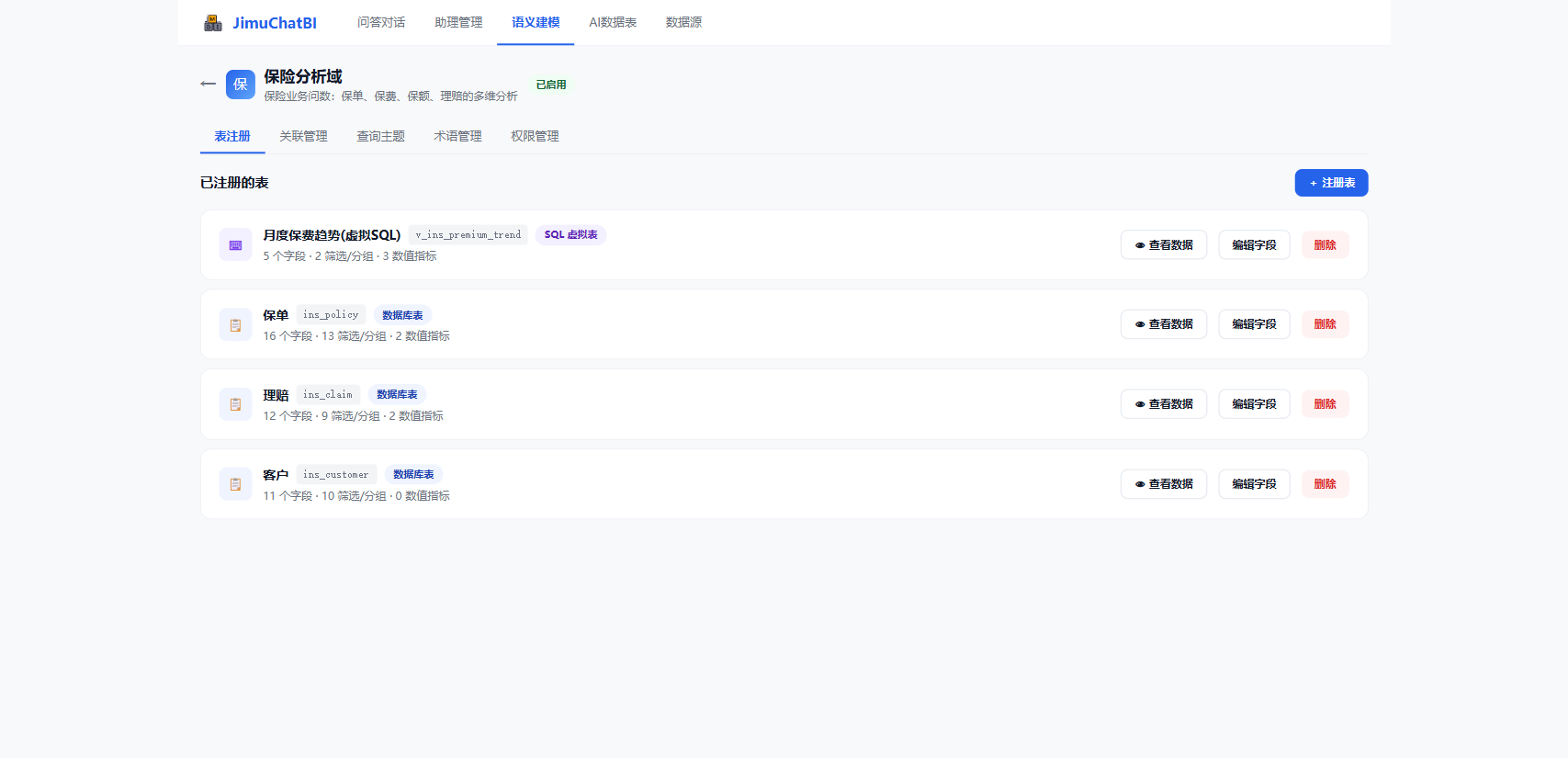
点击 + 注册表,两种方式:
- 📋 选择表:从已有库表选择
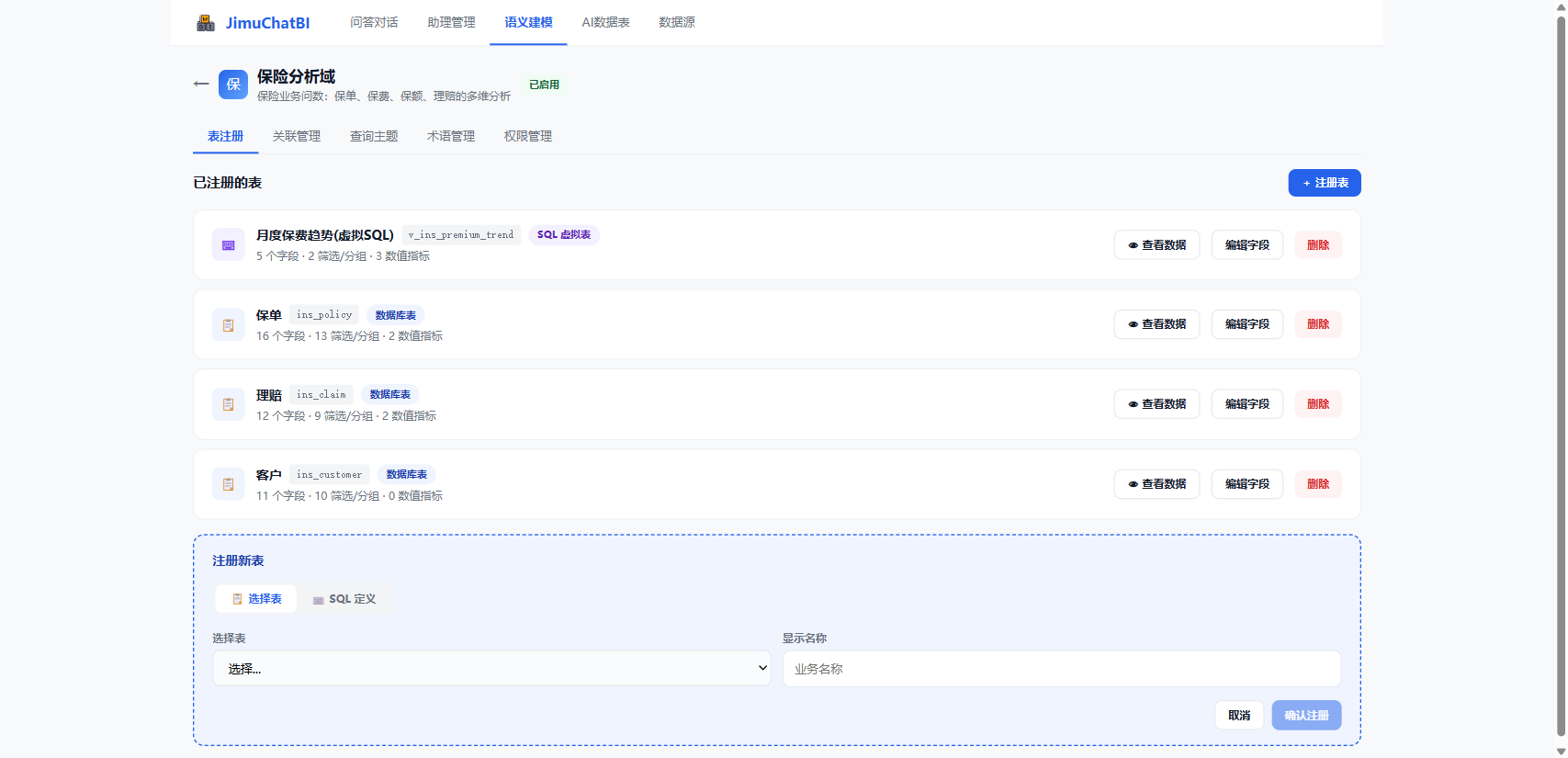
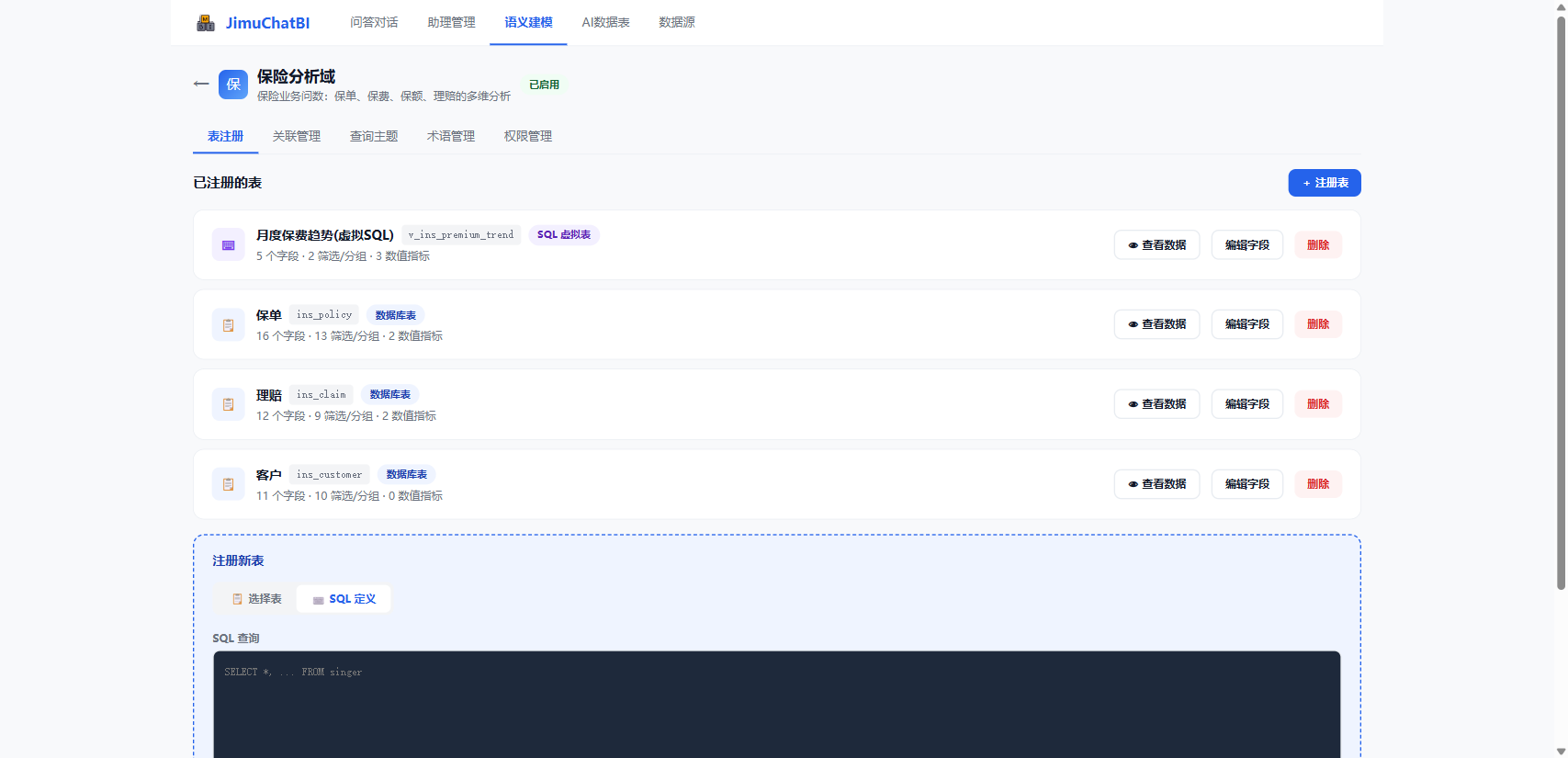
- ⌨️ SQL 定义:写 SQL 作为"虚拟表",点「解析字段」自动识别结果列(适合预聚合、跨表加工)
注册后点 「编辑字段」 逐字段配置:
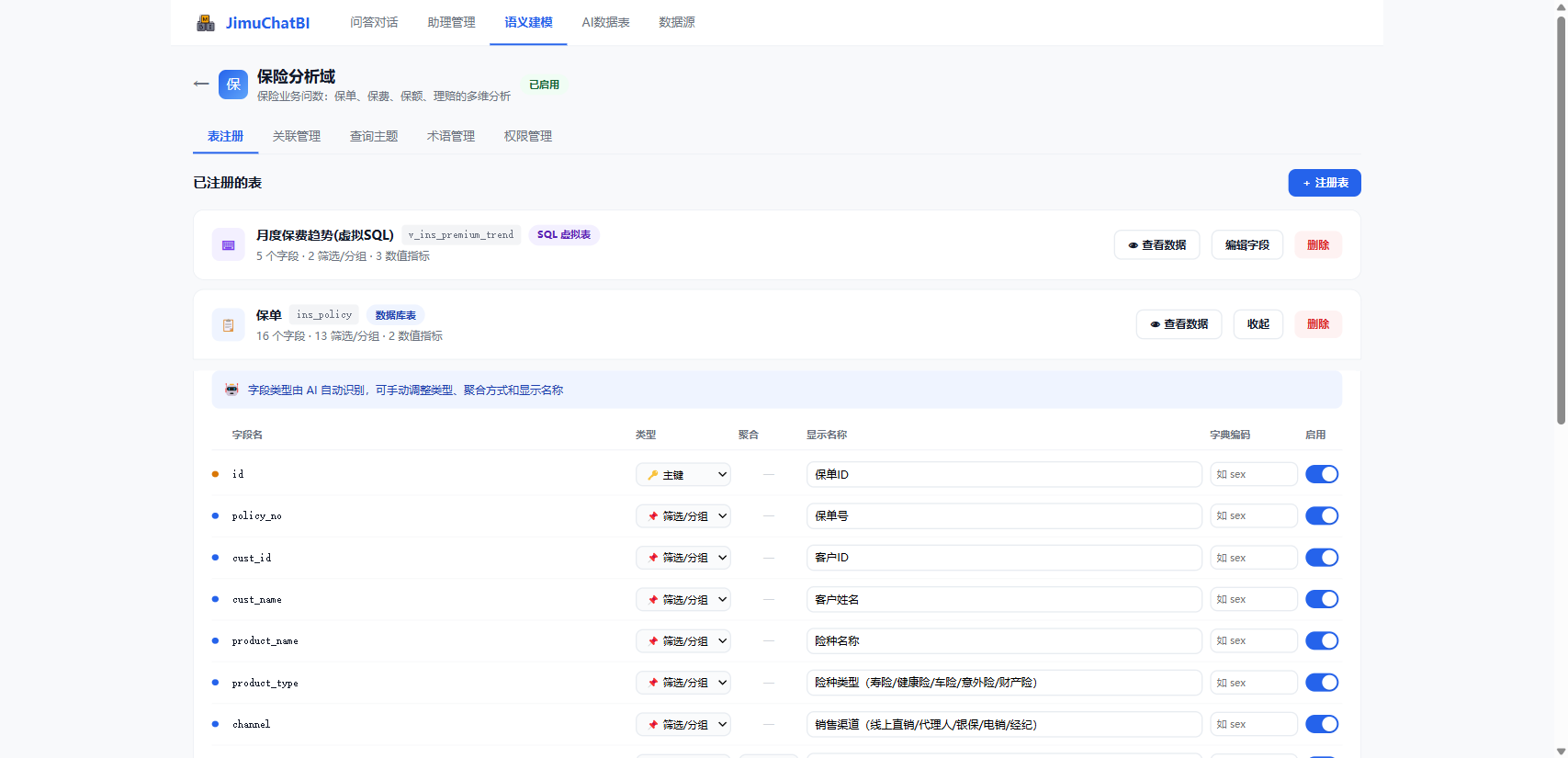
| 配置项 | 说明 |
|---|---|
| 类型 | 🔑 主键 / 📌 筛选-分组(维度)/ 📊 数值指标(度量) |
| 聚合 | 数值指标的聚合:SUM / AVG / MAX / MIN / COUNT |
| 显示名称 | 业务别名,提问与展示都用它(premium → "保费") |
| 字典编码 | 关联字典翻译码值(sex → 显示"男/女") |
| 启用 | 关闭则不参与问数 |
字段类型 AI 自动识别、可手动调整。维度用于分组筛选,数值指标用于聚合——分类准确,结果才正确。
数据域是问数的封闭边界(重要):助理只能查询其绑定数据域内已注册且启用的表,AI 不会自动去扫描或使用数据域之外的库表。因此当用户的问题涉及未注册进本域的表时,助理将无法取数(或提示"该数据域未配置数据表")。需要扩大可问范围时,回到本页 + 注册表 把相关表加入数据域即可。
这是为保证口径可控、结果可信的有意设计:与"让 AI 自由扫描全库、自动匹配表"的开放模式不同,JimuChatBI 用"先建模、再问数"把 AI 约束在你认可的表与字段范围内。
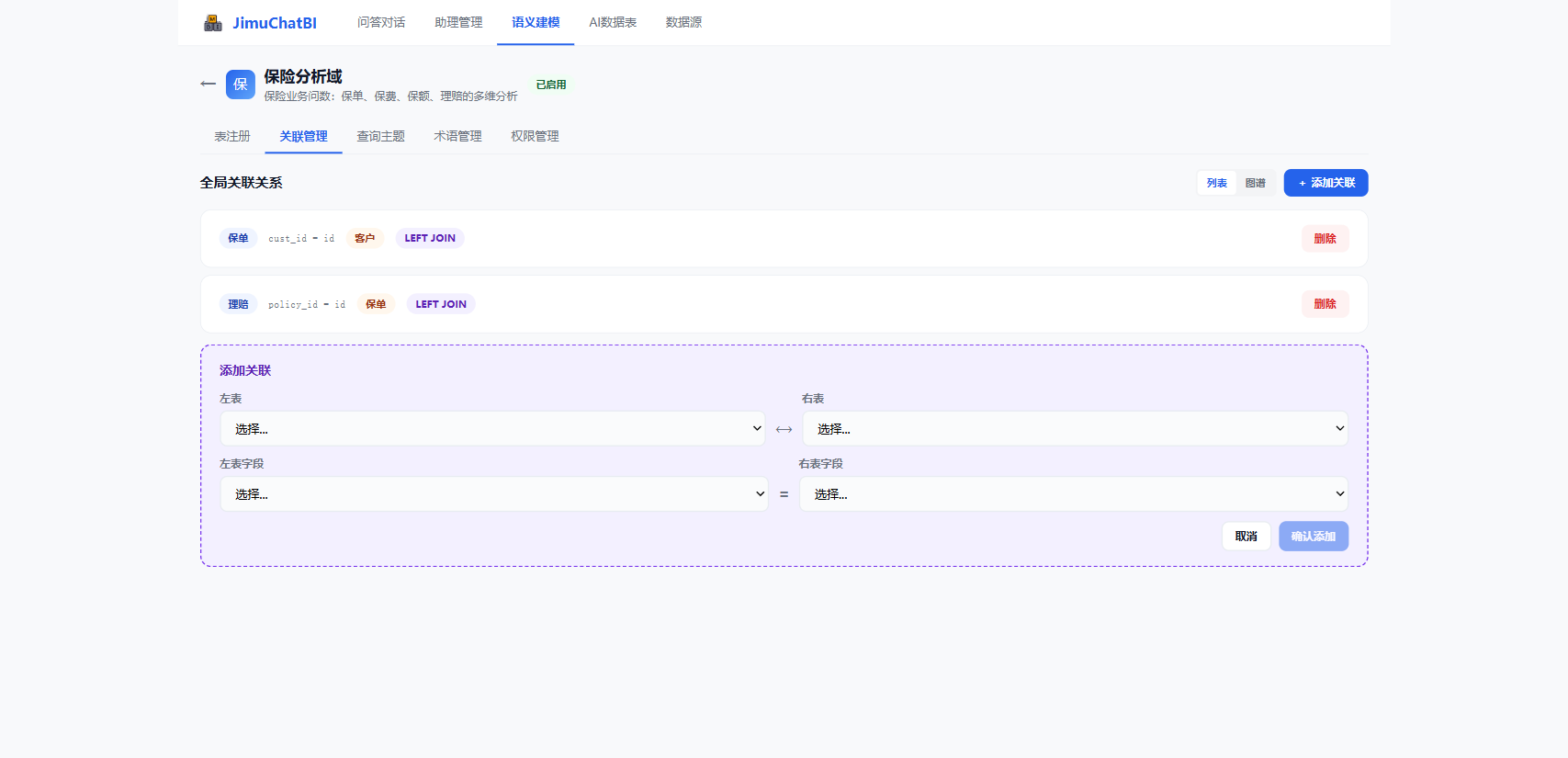
6.2 关联管理
配置多表 JOIN,让 AI 能跨表取数(如"客户的保单明细")。
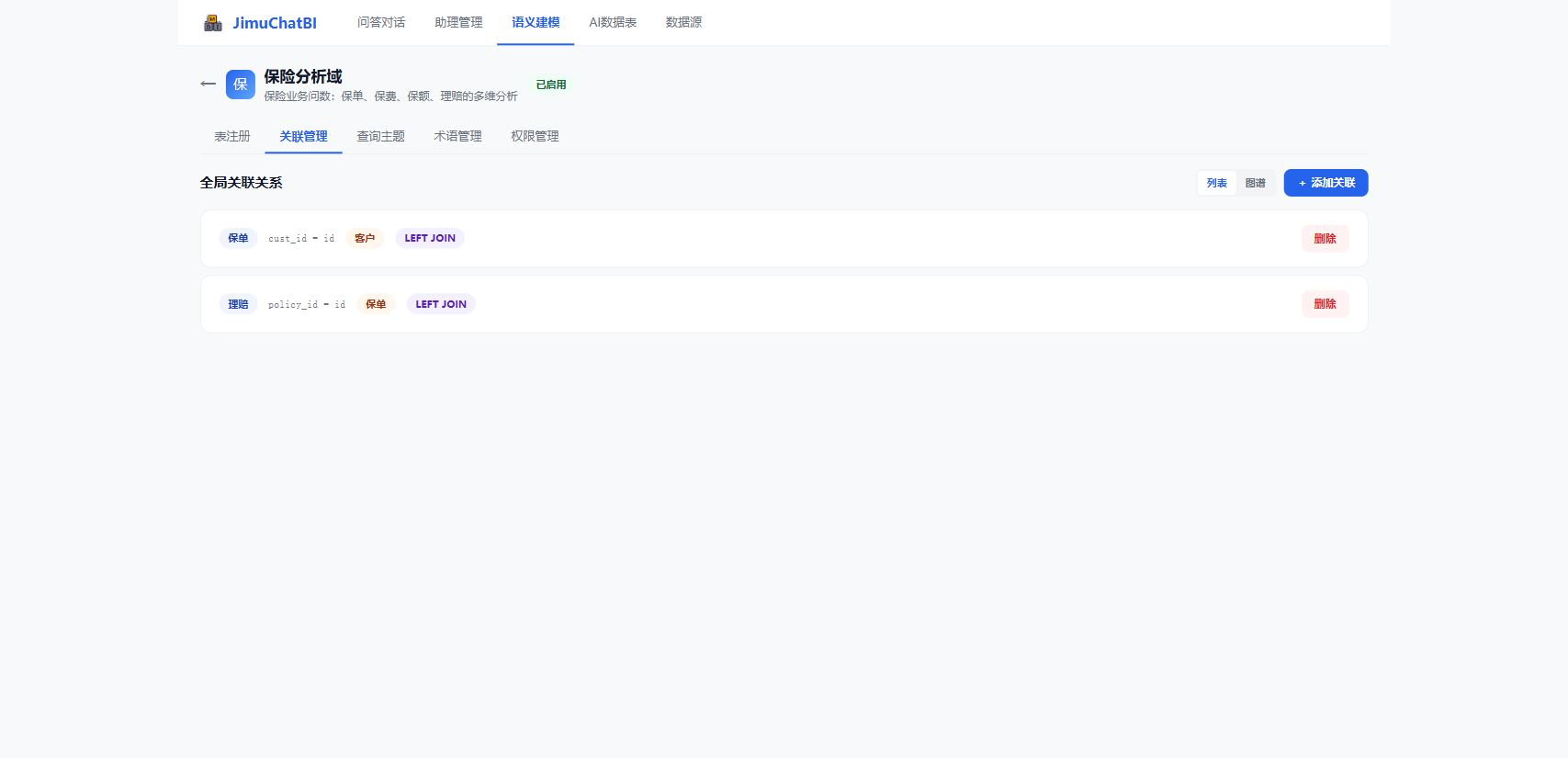
点击 + 添加关联,选左表、右表及关联字段。支持列表 / 图谱两种视图。
6.3 查询主题
把一组常用字段打包成主题,聚焦特定分析范围。
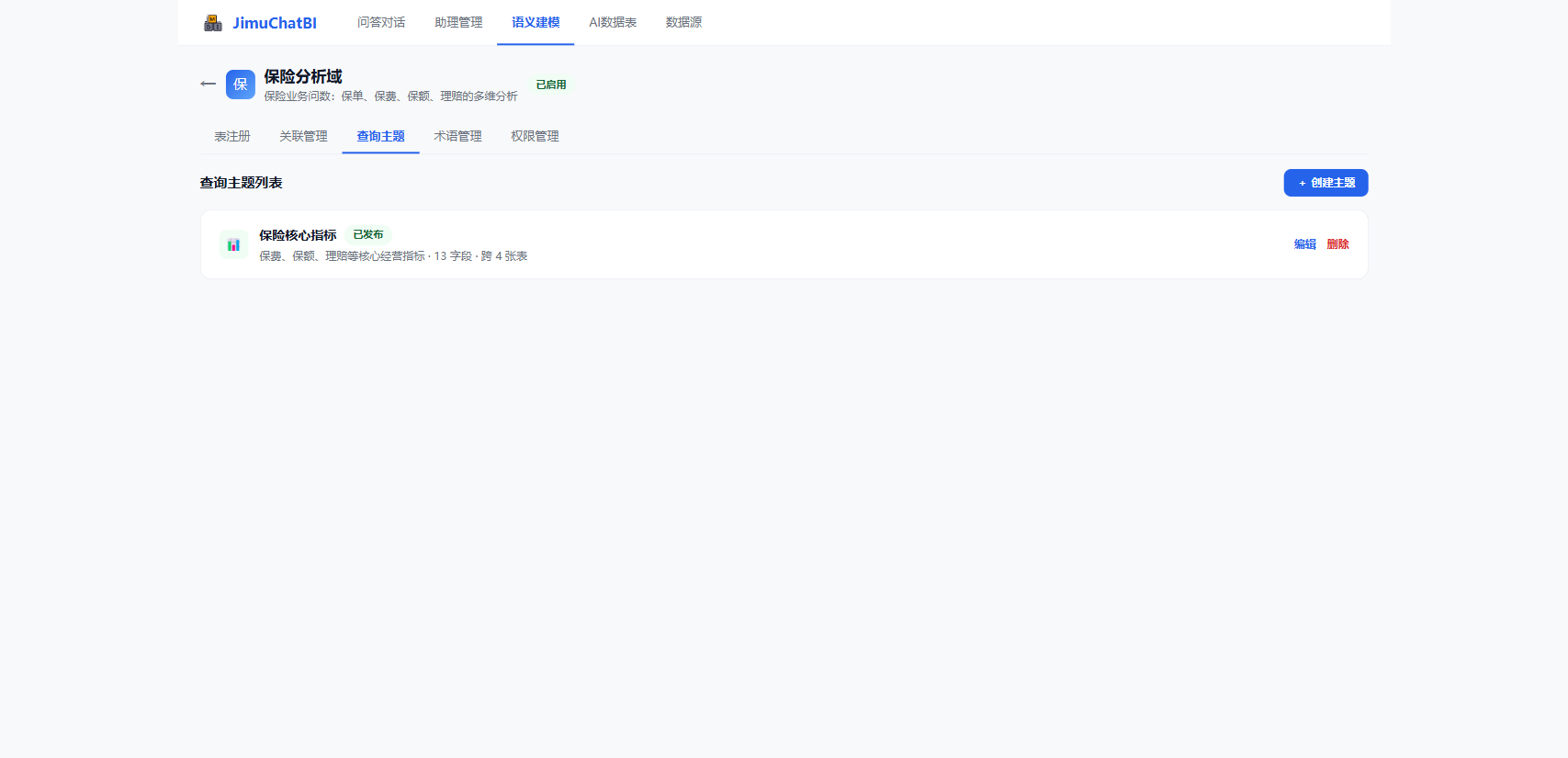
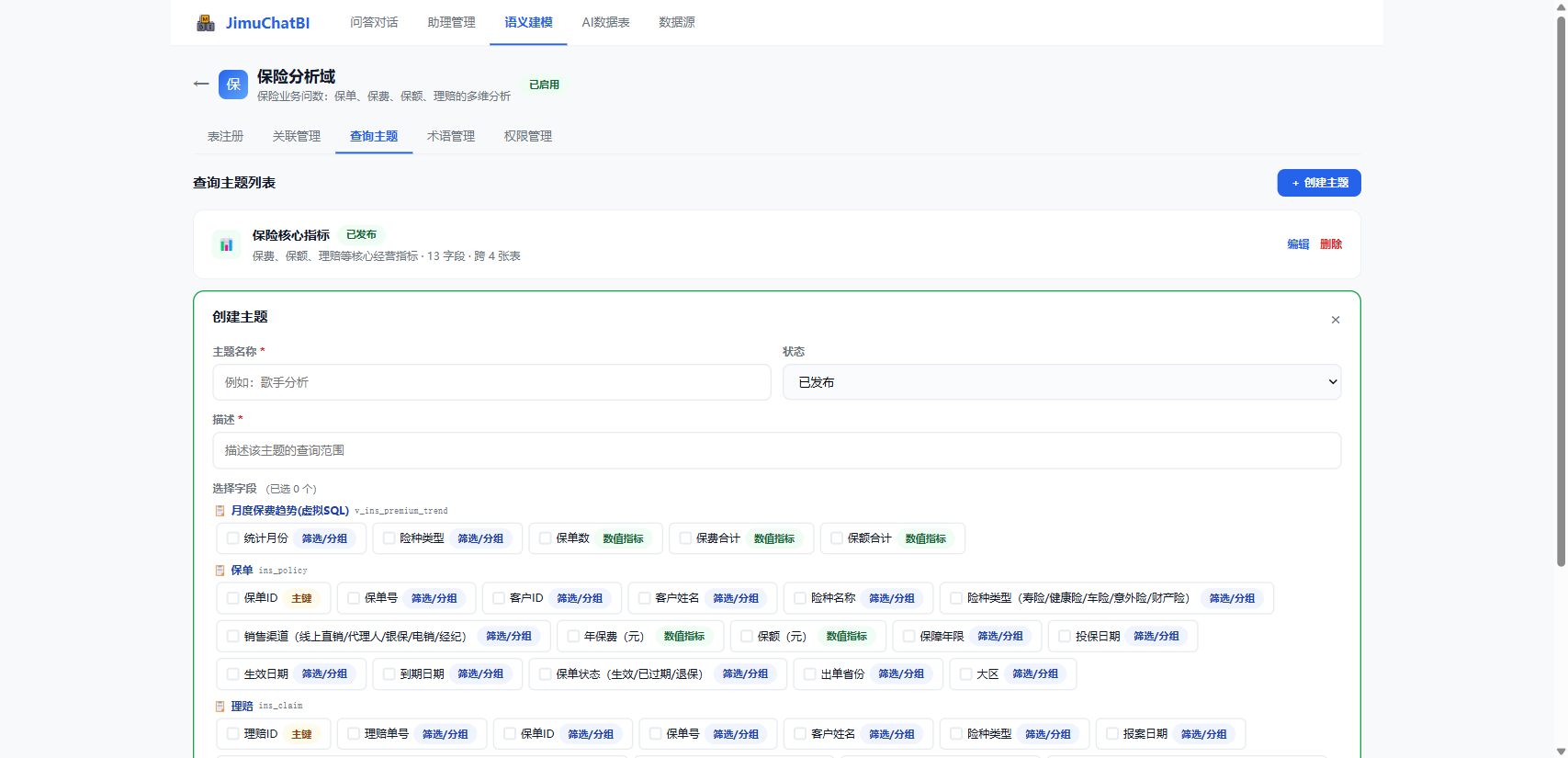
点击 + 创建主题,填名称、描述,勾选字段(可跨表),设为已发布 / 草稿。已发布主题在绑定该域的助理中自动可用。
6.4 术语管理
把业务口语、简称、近义词映射成精确口径。
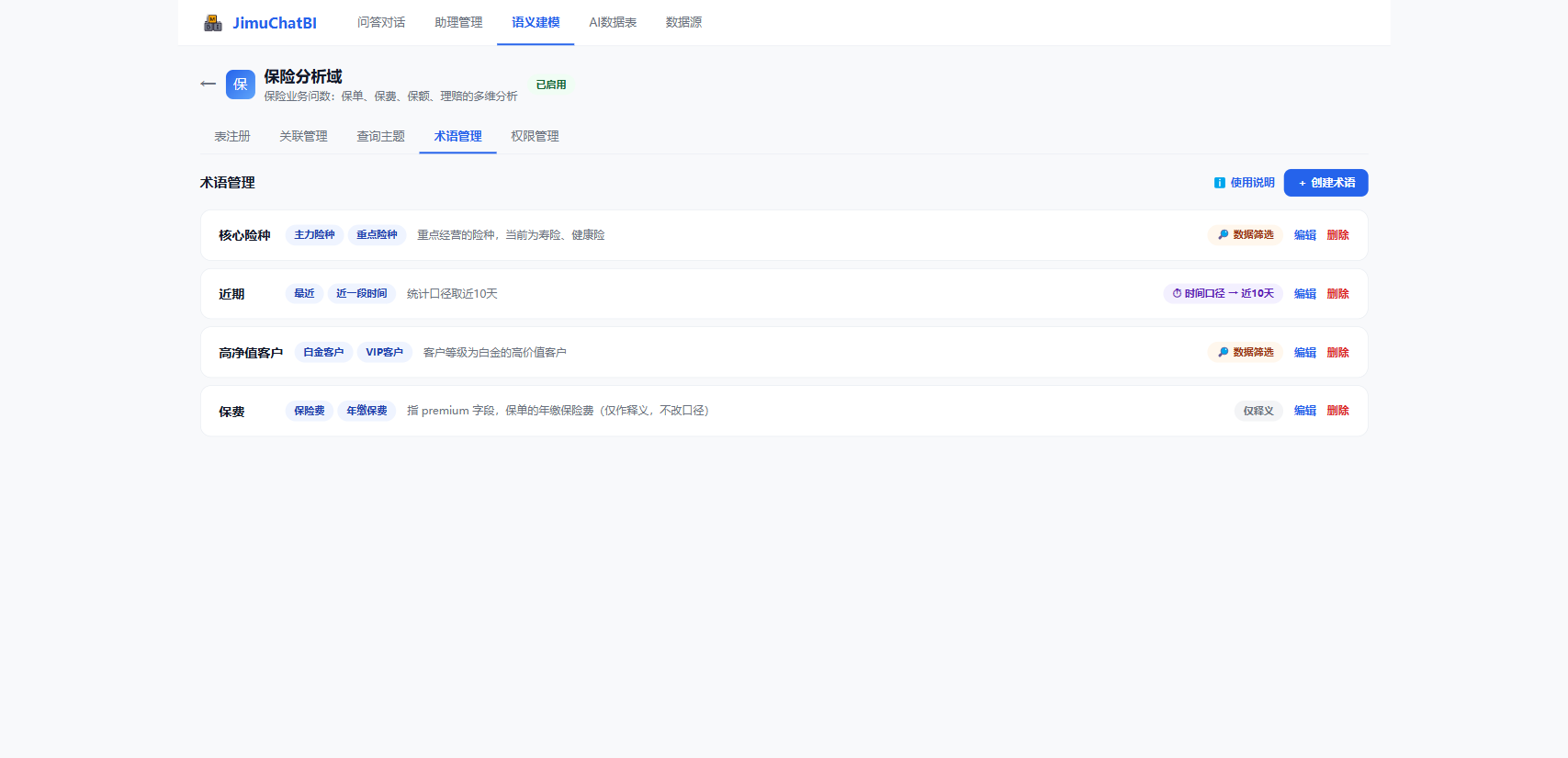
点击 + 创建术语,配置名称、近义词、描述,以及应用为:
- 仅释义:只做名词解释,不改口径
- 时间口径:把时间范围设为指定值(近 10 天 / 本月 / 本季度 / 今年)
- 数据筛选:追加 WHERE 条件(如
product_type IN ('寿险','健康险'))
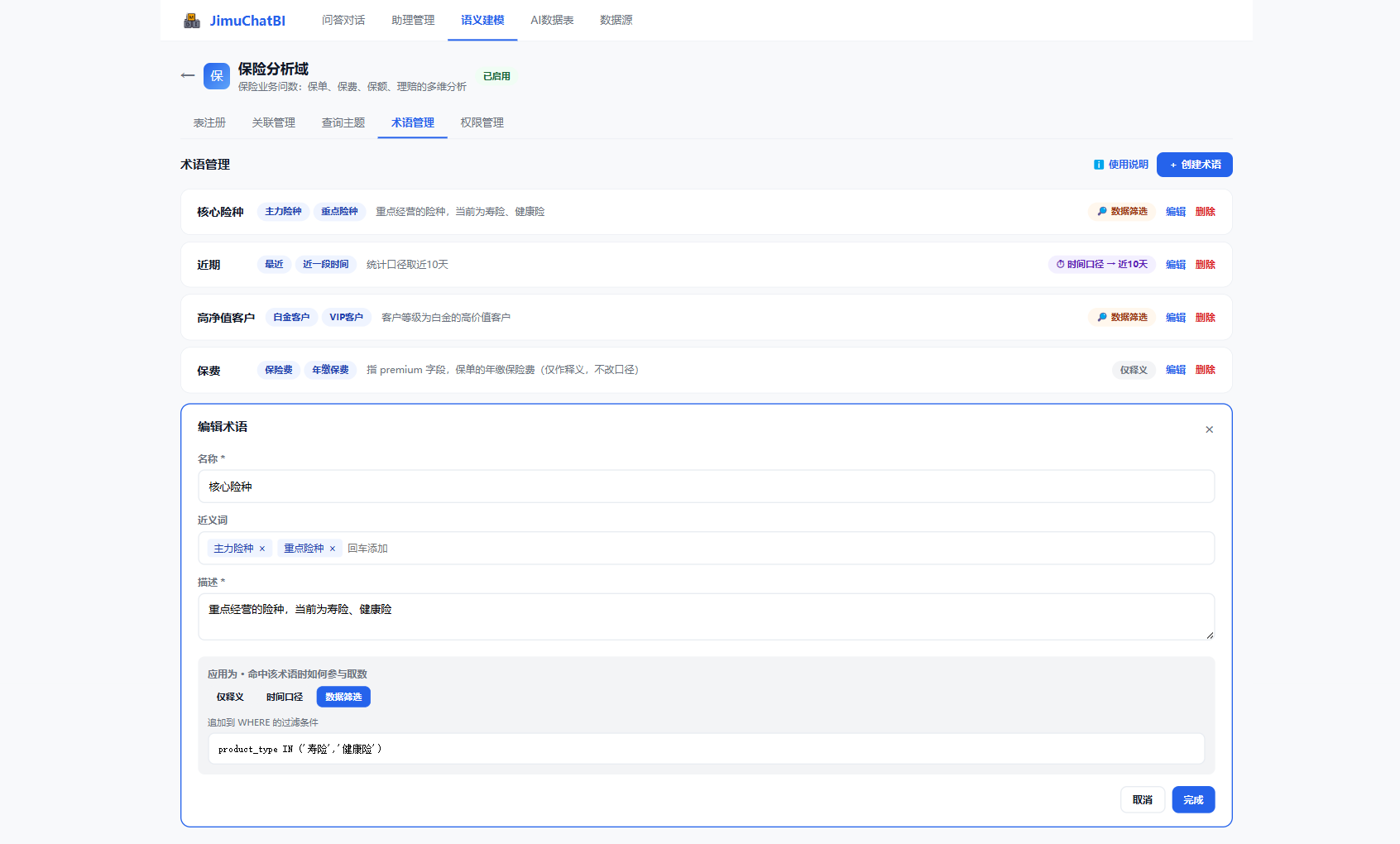
术语注入 AI 提示词、实时生效。配好"核心险种 = 寿险/健康险"后,用户问"核心险种的保费"会自动追加过滤。
6.5 权限管理(安全护栏)
数据域级的多层安全控制。
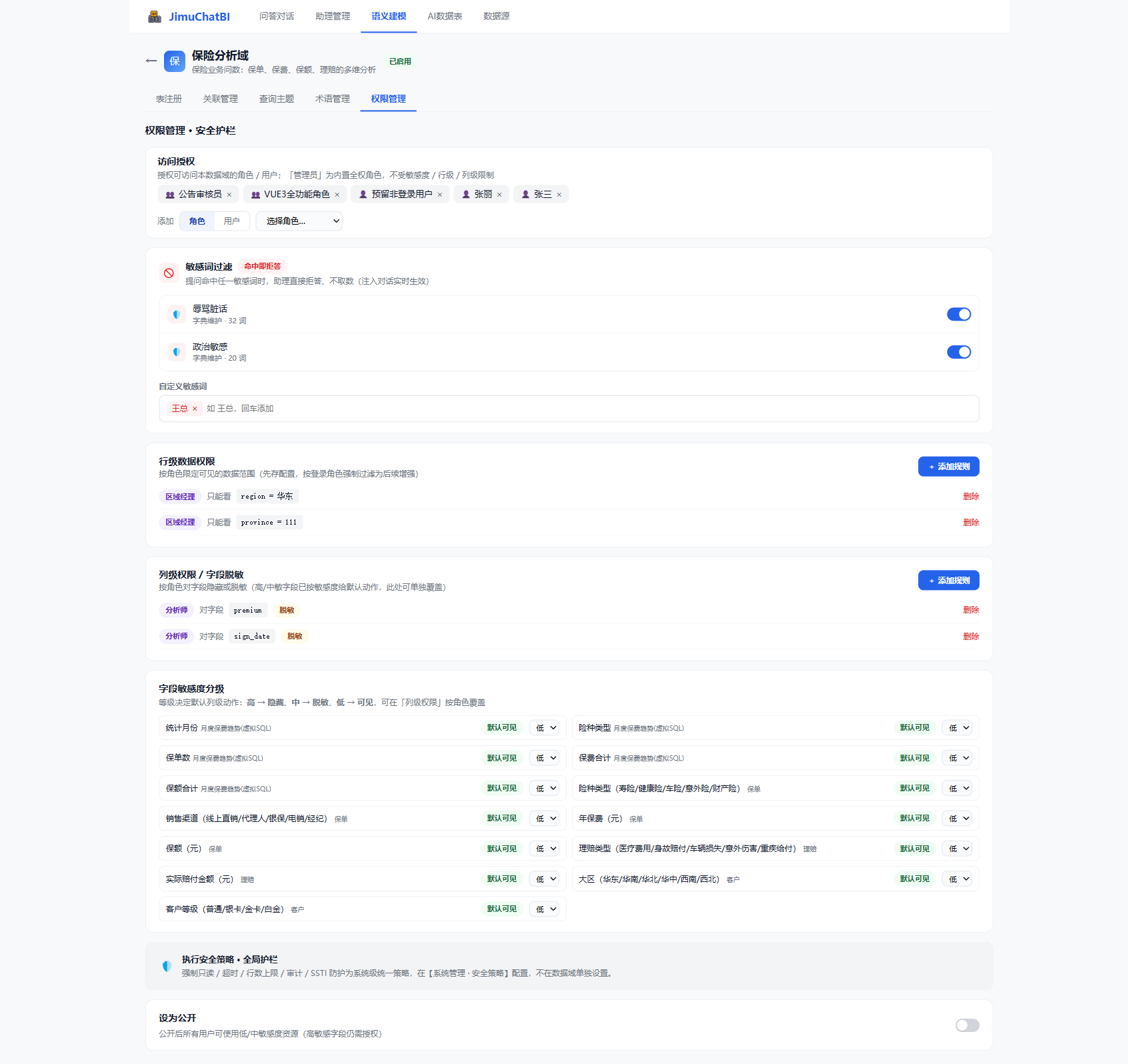
| 配置块 | 作用 |
|---|---|
| 访问授权 | 授权可访问本域的角色 / 用户(「管理员」为全权角色,不受限制) |
| 敏感词过滤 | 命中敏感词即拒答、不取数,支持内置分类(字典 c2b_sens_*)与自定义词 |
| 行级数据权限 | 按角色限定可见数据范围,支持动态值(按登录用户过滤) |
| 列级权限 / 脱敏 | 按角色对字段隐藏或脱敏 |
| 字段敏感度分级 | 高→隐藏、中→脱敏、低→可见,可在列级权限按角色覆盖 |
| 设为公开 | 公开后所有用户可用低 / 中敏感资源(高敏字段仍需授权) |
强制只读、超时、行数上限、审计、SSTI 防护等执行安全策略为系统级统一配置(【系统管理 · 安全策略】),不在单个数据域内设置。
7. 创建对话助理
进入 「助理管理」,点 + 创建助理,4 步向导完成:
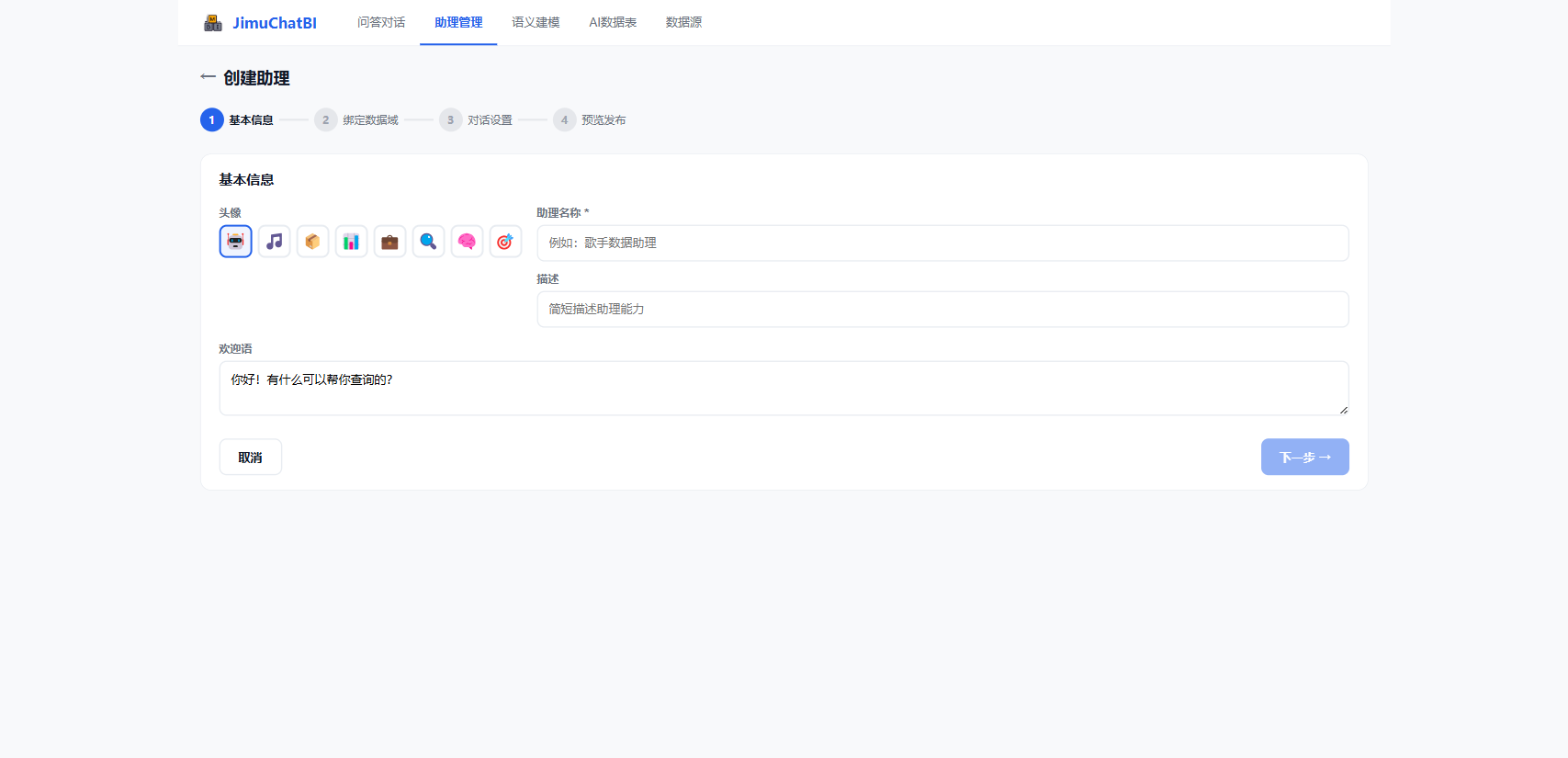
- 基本信息:头像、名称、描述、欢迎语
- 绑定数据域:选可查询的数据域(域下已发布主题自动可用)
- 对话设置:配推荐问题(可「AI 生成」)、开关展示 SQL
- 预览发布:确认后点 「发布上线」
上线后助理出现在「问答对话」列表中,卡片上可随时编辑 / 对话测试 / 删除。助理上线后,业务用户即可进入问答对话取数,详见 问数对话使用。
8. 让问数更准 · 最佳实践
- 补全 AI 描述:给表和字段写清晰描述,提升准确率最有效
- 分清维度与指标:分组字段设"筛选/分组",可聚合数值设"数值指标"并配聚合方式
- 配好表关联:跨表问数前务必在「关联管理」配 JOIN
- 善用术语:把行业黑话、简称定义成术语
- 配字典编码:让码值字段显示为可读文本
- 收敛可见表:只放开需要的表,减少噪音
9. 常见问题
| 问题 | 解决 |
|---|---|
| 提示"AI 模型未配置" | 参考 快速集成 · 配置 AI 大模型 补充 jeecg.jmreport.ai 配置 |
| 无法连接数据源 | 在「数据源」用"测试连接"逐项排查 |
| 助理列表为空 | 到「助理管理」创建并发布上线 |
| 取数结果不对 | 完善 AI 数据表描述、校正字段类型、补充术语 |
| 问了数据域之外的问题,助理答不了 | 数据域是封闭边界,只认已注册且启用的表;到「语义建模 · 表注册」把相关表加入本域 |
| 跨表查询失败 | 在「关联管理」添加 JOIN |
| SQL 虚拟表无法执行 | 在表注册重新「解析字段」并检查 SQL |
| 用户看到不该看的数据 | 在「权限管理」配置访问授权与行 / 列级规则 |
| 提问被拒答 | 检查「权限管理 · 敏感词过滤」 |
10. 设计理念:为什么 JimuChatBI 选择"建模优先"
很多人初次接触对话式 BI,会期待"接上数据库、什么都能问"。但 JimuChatBI 刻意选择了先建模、再问数的路线。 这一节说明背后的两种范式、各自优劣,以及我们的选型原因——理解它,能帮你更好地用对产品。
10.1 对话式 BI 的两种范式
业界做自然语言问数,大体有两条路:
| 范式 | 做法 | 代表诉求 |
|---|---|---|
| 开放式 · 全库自动匹配 | 不预先配置,AI 直接扫描整库,按表/字段名和注释自动挑表生成 SQL | "什么都能问,零配置" |
| 建模式 · 受控问数(JimuChatBI) | 先由管理员做语义建模(注册表、配口径、术语、权限),AI 只在认可的范围内取数 | "数字可信、可治理" |
10.2 两种范式各自的优势
开放式(全库自动匹配)的优势:
- 零配置、开箱即用:接上数据库就能问,无需建模
- 覆盖面广:任何表、任何问题都能尝试作答
- 适合探索:临时取数、摸底"库里大概有什么"很顺手
建模式(受控问数)的优势:
- 口径可控:指标、维度、聚合方式、字典翻译都经人工建模,AI 不会乱算
- 结果可复现:同一问题走同一口径,答案稳定,可放心写进汇报
- 企业级安全:访问授权、行级/列级权限、脱敏、敏感词、敏感度分级——开放式无法做到
- 业务语言对齐:术语映射把行业黑话、简称对齐到精确口径
- 答错率低、可信:边界清晰,"有把握才答"
10.3 为什么我们选"建模优先"
JimuChatBI 面向企业、面向业务用户,因此把"建模优先"作为产品主线,原因有四:
- 企业 BI 的第一诉求是"数字可信",不是"什么都能问"。 一个可能算错的数字比"暂时答不了"更危险—— 错数字会被当真、被写进决策;答不了用户还会去核实。受控问数的"有把握才答",是 BI 该有的诚实。
- 安全与合规是硬约束。 权限边界、数据脱敏、审计在企业里不是可选项;开放式"AI 自由扫全库" 天然无法承载行级/列级权限,存在越权看数风险。建模式把安全护栏内建到数据域里。
- 结果要可复现、可解释。 建模后口径固定,每次问数有据可查(可查看 SQL),方便排错与信任沉淀。
- 与行业方向一致。 成熟的对话式 BI 普遍走"语义层/指标层"路线,正是因为大家都验证过: 全库自由 NL2SQL 在生产环境难以稳定可靠。
一句话总结:JimuChatBI 用"先建模"换"可信"——划定一个你认可的语义范围,在范围内把准确率、安全性、
可复现性做到位。这不是限制,而是企业级 BI 的正确取舍。
10.4 那"建模成本"会不会太高?
建模优先的代价是前期配置,但产品已用几处设计把成本压到最低,首次建模通常十几分钟即可上线一个助手:
- AI 自动识别字段类型(维度/指标/主键),管理员只需校正
- AI 描述、推荐问题可一键生成
- 数据源/表可复用积木报表已有配置
- 建议遵循最佳实践:先放开少量核心表、配好描述与关联即可起步,按需再扩。
当用户问到数据域之外的问题时,助理会明确提示超出范围(而非给出不可靠的猜测)。
如果某类问题被频繁问到,按 6.1 表注册 把相关表纳入数据域即可——让数据域按真实需求逐步生长。